Surveying scholars on characterisations of citations
We designed and scripted a survey in SurveyMonkey. We then invited all members of the Elsevier's CDI Researcher Innovation Community to fill in the survey by e-mailing a direct link. From the 1200+ members of the community, we received 318 completed responses. The CDI Researcher Innovation Community is an in-house, carefully curated panel composed of researchers with wide representation across career phases, disciplines and regions. Elsevier has built this community up over 3 years, it is by invitation only and utilised for both qualitative and quantitative research.
We asked the respondents to our questionnaire to figure themselves as a user of a platform which gives access to full texts articles together with bibliographic references, and additional information on the articles cited by a given one (outgoing citations) as well as on articles citing that one (incoming citations). The full text of the questionnaire is available on-line .
The first part consisted in rating the relevance (from 0 to 5) of 13 characterisations for both incoming and outgoing citations, as well as impact factors of the articles authors, with the possibility each time to suggest other information through a free text box. We did not show all properties covered in previous section merely to keep duration of the test as low as possible. The characterisations submitted are: is extended by, same research problem, supported by or criticised by, use method in, global citation count, data sources, most cited authors, type of publication venue, type of content, self-citations, citation context, in paper citation count, section in which cited. Each of these characterisations can be used for outgoing and incoming citations, and within the questionnaire, both cases were presented each in a different section and a detailed explanation was given for each characterisation.
A final part of the survey was collecting info about the background of the respondents, focusing on the research domain, role, and habits regarding the use of digital scholar libraries.
To compare the different characterisations, we calculated, for each of them, the weighted score of relevance, the score's possible value ranging from 0 (not relevant) to 5 (very high relevance). Given the percentage p(s) of response for each score s, the weighted score S is obtained by summing for each score value s the product p(s) * s. reports the weighted score for all citation characterisations for outgoing and incoming citations.
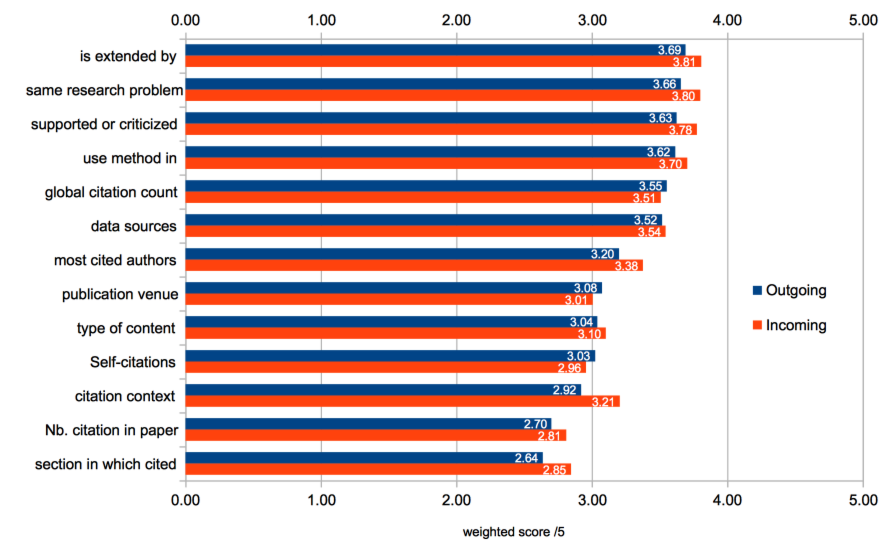
The values of the weighted score range from 2,61 (section in which cited for outgoing citations) to 3,78 (is extended by for incoming citations). Therefore all characterisations remain around the medium score, i.e 3. The standard deviation for each calculation of the weighted score range from 1 to 1,3 across all the cases. This level of standard deviation accounts for the relatively flat distribution of the ratings of all respondents.
Several remarks can be drawn from the global results:
-
Due to the small amplitude and to a standard deviation not negligible, it is not straightforward to establish a significant ranking among the highest scored characterisations, nor to discard the characterisations with the smallest score. This means that all of them can be considered of relative interest for the majority of the respondents.
-
Looking at the group of 7 chracterisations whose weighted score is above 3, one can observe that the 4 most highly scored characterisations (both for incoming and outgoing citations) are citation functions and that the only factual features are all related to the global citation count (global citation count and most cited author).
-
The highest gap between the weighted score value of incoming and outgoing citations for a given characterisation is found for the citation context (3,21 for incoming, 2.92 for outgoing). This shows that this information is more valuable when given for the citing articles than for the cited ones.
The free text box inviting testers to suggest additional characterisations was skipped or given a "none" or equivalent response by 95% (incoming citations) and by 85% (outgoing citations) of the respondents. Although this does not demonstrate that the above list of 13 citation characterisations is complete, it gives us a pretty good hint in showing that the most wanted characterisations were covered in our listing. We were only suggested two properties to add to our list: year of publication and impact factor of the venue in which cited work was published.