Surveying scholars on characterizations of citations
Questionnaire
We asked the respondents to our questionnaire to figure themselves as a user of a platform which gives access to full texts articles together with bibliographic references, and additional informations on the articles cited by a given paper (outgoing citations) as well as on articles citing this paper (incoming citations). The first part consisted in rating the relevance (from 0 to 5) of 13 characterizations for both incoming and outgoing citations, as well as impact factors of the articles authors, with the possibility each time to suggest other information through a free text box
We shape the questionnaire according to the model we had in mind, but we did not show the whole model (covered in previous section) merely to keep duration of the test as low as possible. Hence the characterizations submitted are: is extended by, same research problem, supported by or criticized by, use method in, global citation count, data sources, most cited authors, type of publication venue, type of content, self-citations, citation context, in paper citation count, section in which cited. Each of these characterizations can be used for outgoing and incoming citations, and within the questionnaire, both cases were presented each in a different section and a detailed explanation was given for each characterization . A final part of the survey was collecting info about the background of the respondents, focusing on the research domain, role, and habits regarding the use of digital scholar libraries.
Results
Distribution across disciplines
We obtained in total 318 responses for this questionnaire. Respondents were coming from all continents, many different background, occupying academic positions spanning from PhD student to senior researchers, and from all main academic disciplines. To distinguish generic classes of disciplines, we have used the decomposition into 24 specific disciplines grouped in 4 broad categories used in Science Direct. The latter are given below with the percentage of respondents it represents:
-
Life Sciences (LS, 17%) which includes more specifically e.g. Agriculture and Biological Sciences, Environmental Sciences, etc.;
-
Health Sciences (HS, 12%) which comprises Medicine and Dentistry, Nursing and Health Professions, etc.;
-
Physical Sciences and Engineering (PSE, 42%), comprising Mathematics, Computer Science, Chemistry, etc.;
-
and Social Sciences and Humanities (SSH, 29%) including Economics, Psychology (psy), etc.
If we group Life Sciences and Health sciences, for they share common roots in biology, we get a rather even distribution between PSE, SSH and the group Health and Life Sciences.The 24 specific disciplines are not as evenly distributed, but we have nonetheless analyzed the detailed results for those specific disciplines that represented more than 5% of the total respondents group. These disciplines, representing 47% of all respondents, are: Engineering, 11.5%; Economy, 8.18%; Computer Science, 7.4%; Medicine and Dentistry, 7%; Agriculture and Biological Sciences, 6.7%; and Chemistry, 6.3%.
The balanced distribution across the main broad disciplines makes the global results obtained in this questionnaire representative of the scientific community. We first present the global results and detail when relevant domain specific peculiarities.
Citation characterizations
To compare the different characterizations, we calculated, for each of them, the weighted score of relevance, the score's possible value ranging from 0 (not relevant) to 5 (very high relevance). Given the percentage p(s) of response for each score s, the weighted score S is obtained by summing for each score value s the product p(s) * s. reports the weighted score for all citation characterizations for outgoing and incoming citations.
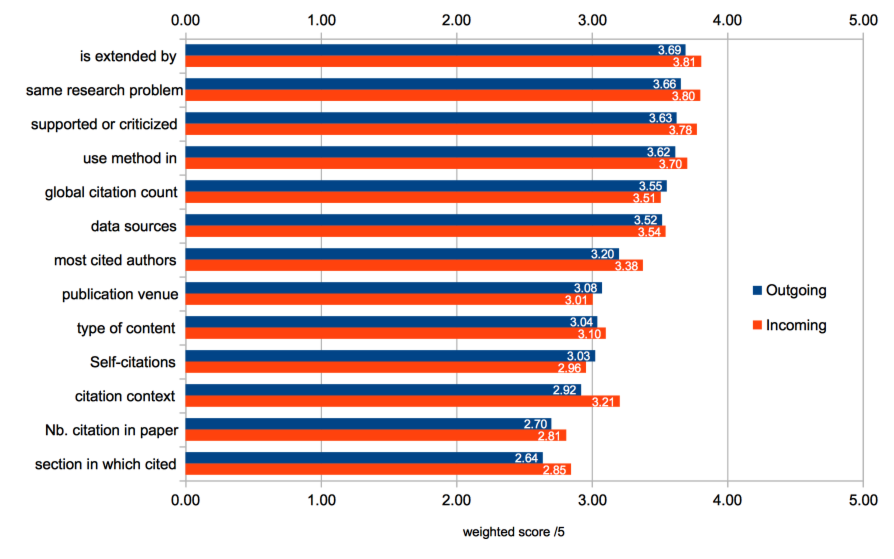
The values of the weighted score range from 2,61 (section in which cited for outgoing citations) to 3,78 (is extended by for incoming citations). Therefore all characterizations remain around the medium score, i.e 3. The standard deviation for each calculation of the weighted score range from 1 to 1,3 across all the cases. This level of standard deviation accounts for the relatively flat distribution of the ratings of all respondents.
Several remarks can be drawn from the global results:
-
Due to the small amplitude and to a standard deviation not negligible, it is not straightforward to establish a significant ranking among the highest scored characterizations, nor to discard the characterizations with the smallest score. This means that all of them can be considered of relative interest for the majority of the respondents.
-
Looking at the group of 7 chracterizations whose weighted score is above 3, one can observe that the 4 most highly scored characterizations (both for incoming and outgoing citations) are citation functions and that the only factual features are all related to the global citation count (global citation count and most cited author).
-
The highest gap between the weighted score value of incoming and outgoing citations for a given characterization is found for the citation context (3,21 for incoming, 2.92 for outgoing). This shows that this information is more valuable when given for the citing articles than for the cited article.
The free text box inviting testers to suggest additional characterizations was skipped or given a "none" or equivalent response by 95% (incoming citations) and by 85% (outgoing citations) of the respondents. Although this does not demonstrate that the above list of 13 citation characterizations is complete, it gives us a pretty good hint in showing that the most wanted characterisations were covered in our listing. Out of the few suggestions we received, the year of publication and the impact factor of the venue in which cited work was published were the most frequent.
Loking at the domain specific results, the global citation count gains less interest in the Health Science community, both for outgoing and incoming citations. In the outgoing and in the incoming citations rankings, this characterization falls at the 9th position (5th position for the global results) and, in absolute, it also gets smaller weighted scores of 3.09/5 (outgoing) and 3.14 (incoming) with respect to 3.55 and 3.51 in the global results.
The same tendency of distrust towards citation count is observed in chemistry where both most cited author and global citation count fall to respectively the last and 3rd to the last positions, in contrast to their 7th and 5th position in the global results. Another observation that reinforces this impression is the strikingly high rank chemists give to self citations. In both outgoing and incoming cases, this property ranks respectively at the 4th and 6th position while it lags behind at the 10th and 11th position for the global results. Being reluctant at giving priority to the most cited works and authors, chemists tend to be in the same fashion more willing to know which authors cite themselves.
Looking at other specific domains, the contrary can be observed in the economics community that clearly evaluates the global citation count as the most interesting characterization for both outgoing and incoming cases. Indeed, the weighted score in this case tops off at 3.91 (outgoing) and 3.77 (incoming) distancing even more clearly than in the global results the second most praised characterization, i.e same research problem in this case. This phenomenon is also observed for the broad category Social Sciences but only in the outgoing case with the global citation count clearly ranking first with a weighted score of 3.83, with respect to 3.55 in the global results and with respect to the second characterization in this category rated on average 3.70
Regarding the highest ranked characterizations some subtleties can be observed in Chemistry, Medicine, and Computer Science.
In chemistry, the use method in characterization ranks more clearly at the first position in both incoming and outgoing case, distancing the second by 0.18 and 0.06 point instead of 0.01 and 0.03 point in the global results. This is maybe explained by the highly experimental nature of chemistry.
In Medicine, the data source characterization ranks first but in the outgoing case only and by distancing the second by 0.05 point. Again, this slight shift in the top characterizations towards giving more importance to the provenance of data can be easily understood in the medicine case.
Finally in Computer Science, we merely observed that the most praised characterization is more clearly than in the global case the address the same research problem characterization. This characterization out-stands its followers by 0.25 (outgoing) and 0.2 (incoming) points, peaking at the highest average grades, all disciplines put together, of respectively 4.30 and 4.20.
Author's impact factors
The importance given to the global citation count is confirmed by the next question we asked about the evaluation of the impact of the authors of academic publications. Similarly to the previous question in the test, we asked testers to rank the relevance (from 0 to 5) of the following impact factors:
-
citation count, i.e. the total number of times an author's contribution has been cited by another academic work.
-
h-index, i.e a compund citation count including the productivity of an author.
-
academic longevity, i.e. the number of year an author has been working and publishing on the same domain.
-
number of downloads, i.e. the number of times an author's contribution has been downloaded by a user of the current digital library.
-
mentions on social networks or on-line news sites
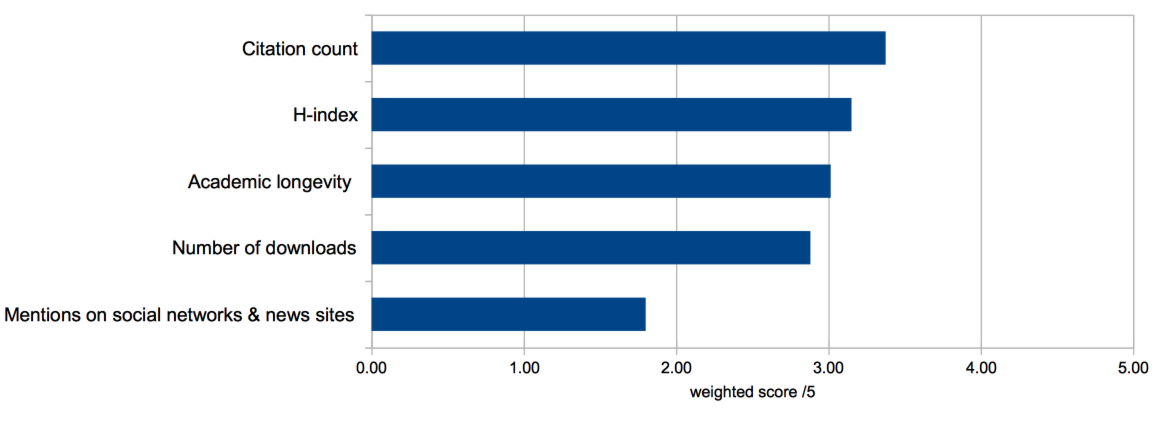
The global results of the weighted score for each of these impact factor (reported in ) show that the citation count remains clearly the most praised indicator of the impact of an author with a weighted score of 3.38/5. 3 impact factors are coming after, which are all relatively close to each other and still gain a relevance score close to 3/5. The clearly least relevant impact factor is the number of mentions within social networks or on-line news site with a weighted score of 1.80.
Regarding the influence of whether we are dealing with outgoing or incoming citations with respect to impact factors, we asked testers if they find this indicators useful for both or only incoming o outgoing citations. Respondents answered "both" in 82% of the cases.
As a conclusion on this point, we can note that the established citations count keeps its authority, alternatives are gaining recognition, but the visibility research works manage to drag in the social networks has yet to convince academics of its reliability. The global results remain almost identical across broad domain categories, but some slight variations can be observed.
The citation count is hence not always the most praised impact factor. Indeed the Health Sciences community places the h-index at the first place with a weighted score of 3.36/5 instead of 3.15/5 for the citation count. Looking at finer grained categories, this very result is naturally confirmed for the Medicine community. Similarly, for the chemistry community the academic longevity (2.65/4) outranks both citation count (2.56) and h-index (2.53). This last result confirms a distrust towards citation-based metrics already observed for this community in the citation characterizations seen above.
The number of mentions on social networks is always the least appreciated of all impact factors. Nuances can be observed tough, such as with the computer scientists who despise it the least with a weighted score of 2.25 instead of 1.80, and the chemists are those to give it the smallest weighted score of 1.12. The number of downloads never outranks the 3 first indicators in the global results, but it sometimes matches the score of academic longevity for the economists or the h-index for the chemists.